 人工智能大讲堂
人工智能大讲堂
18世纪末至19世纪中叶的第一次工业革命,蒸汽机的发明替代了人力,开启了机器代工的时代。
19世纪末至20世纪初的第二次工业革命,电力和内燃机的应用大幅提升了生产效率和自动化水平。
20世纪末至21世纪初的第三次工业革命,计算机和互联网的广泛连接彻底改变了信息的处理和传播方式。
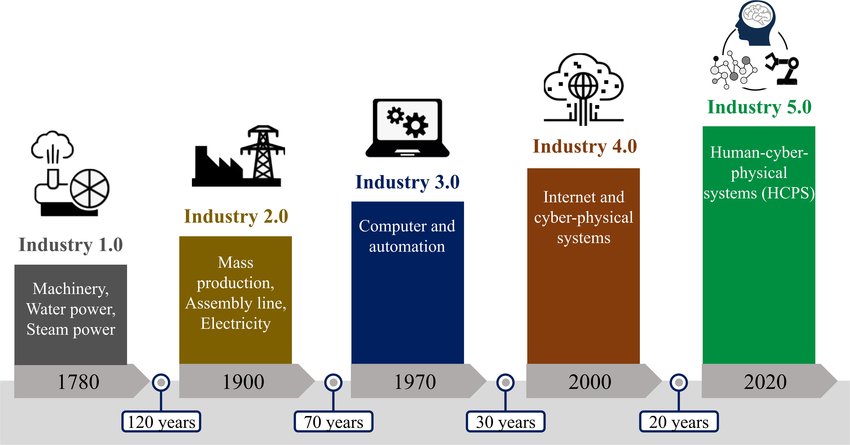
当下,世界正在进入了以智能技术与系统为主导的第四次工业革命的新时代。
什么是AI?
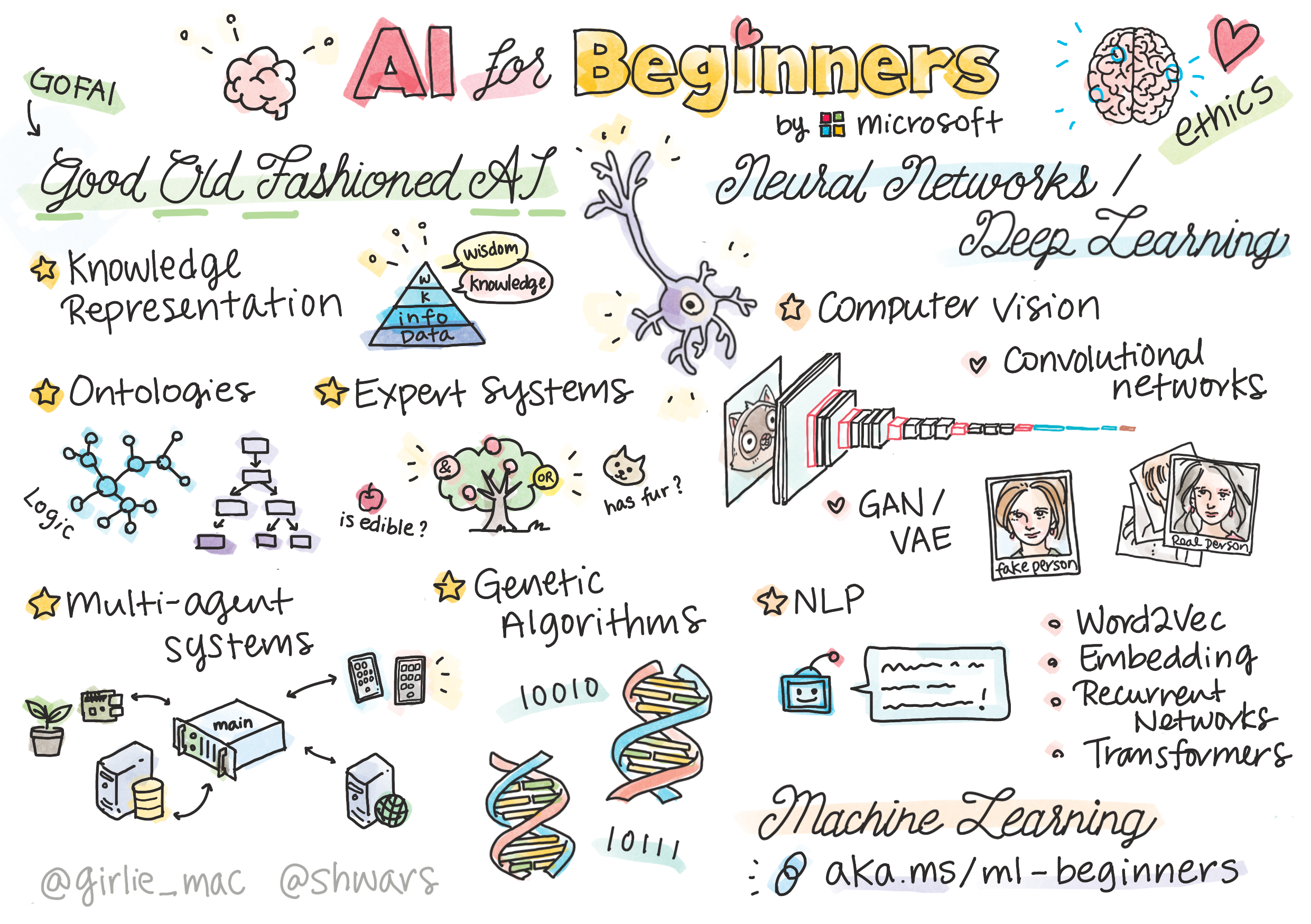
其实在AI出现以前,人类已经能通过编码让计算机执行特定任务。比如:
if(con)
{
do something
}
else
{
do something
}
但是,这种硬编码方式难以完成更复杂的工作,比如面部识别年龄。

要让计算机获得这种智能,就需要一种使其能学习的方法,也就是人工智能。
起初人类对于智能并没有一个明确的定义,图灵测试是一种方法,或者像Alphago对战李世石那样,与人类智慧对比。
但总体上讲,人工智能可以分为两类,一类只能完成某种特定任务,称为弱人工智能,与之对应的是强人工智能,也被称为通用人工智能。
当下流行的生成式AI被认为是实现通用人工智能的必经之路。
如何实现AI?
既然希望计算机能够表现得像人类一样,就要让计算机模拟人类的思维方式。
因此,我们需要了解人类是如何做决策的。
一种是自顶向下的方法(符号推理),模拟人类解决问题的推理方式。它涉及从人类获取知识,并以计算机能理解的方式给它。也被称为符号主义AI,典型的代表是专家系统。
另一种是自底向上的方法(神经网络),模拟人脑的结构,它由大量称为神经元的简单单元组成。智能源自于概念之间在神经网络中的联结。也被称为连接主义AI。
起初,符号推理是一种流行的方法。但这种方法并不适合大规模应用。
随着计算资源,数据增加,神经网络方法(连接主义方法)开始成为主宰。现在我们听到的大部分人工智能的成功都是基于它们的,包括生成式AI。
但两者也不是完全对立的,许多强大的模型都是通过巧妙融合两种方法的成果。例如CNN+SVM,前者提取特征,后者进行分类。
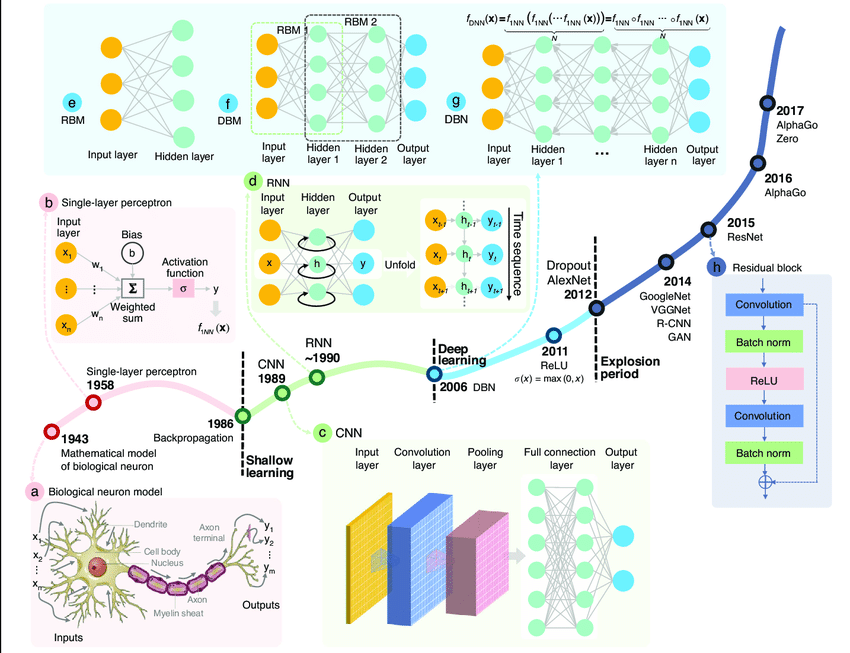
AI的发展历史
尽管科技的进步势不可挡,但人工智能的发展之路并不平坦,让我们回顾一下AI所经历的坎坷。
“创新的技术在一开始总是被人们误解的。” —艾伦·凯伊
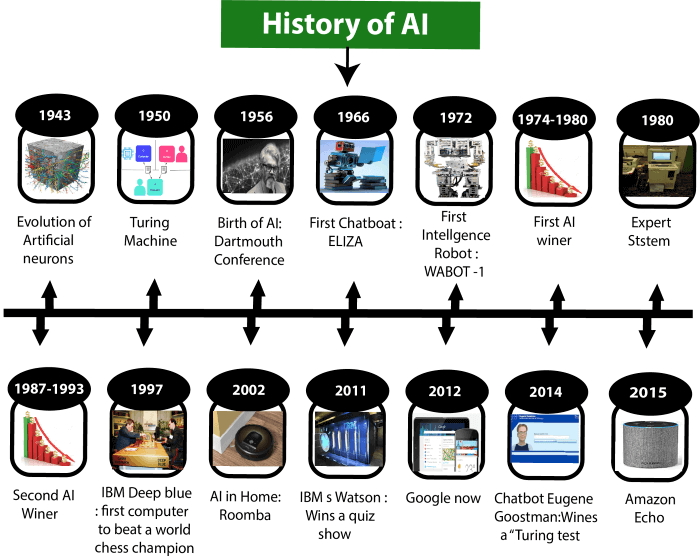
1950年英国著名数学家,计算机科学家图灵在其论文中提出:“机器是否能够表现出与人类一样的智能?”,为了回答这个问题,他提出了一个实验,即图灵测试。
此时,大洋彼岸的新中国刚成立一年,万事百废待兴。
1956年的达特茅斯会议,被认为是人工智能领域的创始会议,共同探讨并提出了人工智能的研究方向和目标。
同一年,约翰·麦卡锡提出了“人工智能”这个术语。从此,人工智能概念正式诞生。
新事物的出现引来了资本和学术界的关注,1956-1966可谓人工智能的黄金十年。
1957年,受生物神经元启发,弗兰克·罗森布拉特发明感知机,它也被视为神经网络的雏形。
1962年,Arthur Samuel制作出可以下棋的电脑程序。
1965年,Weizenbaum开发出ELIZA对话系统。
1969年马文·明斯基等人指出弗兰克·罗森布拉特发明感知机无法解决异或问题。
AI原本被寄予厚望,但技术的瓶颈使其在商业上并未取得成功,给人留下了不切实际的印象,导致资本和学术界开始对人工智能失去信心,人工智能开始步入第一个漫长的寒冬(1974-1980)。
而此时的中国正在开展无产阶级文化大革命运动。
1980年出现的专家系统仿佛又让人们看到了希望,它是一种模拟人类专家进行推理和解决问题的人工智能程序。其目的是将专家的领域知识和经验编码成系统,从而取代人工解决特定领域的问题。
但专家系统仍然无法兑现被高度夸大的诺言,未能推广到更多领域,导致资本开始流向计算机,互联网等新兴技术,AI进入第二次寒冬(1987-1993)。
而此时的中国正在进行改革开放,大力发展经济。
1997年,二番战,IBM的深蓝超级电脑击败国际象棋冠军加里-卡斯帕罗夫。这标志着游戏人工智能系统取得重大进展。
1998年,Yann LeCun团队提出的卷积神经网络LeNet,为后来的深度学习奠定基础。但由于数据和算力的因素,当时人工智能仍处于相对冷清的时期。
2012年,AlexNet在视觉识别竞赛ImageNet中获得历史性的胜利,深度学习开始流行。
随着互联网的发展,数据的获取变得容易,在摩尔定律的推动下,算力不断增长,AI又重新回到人们的视野。
2016年,AlphaGo击败李世石,标志着深度学习在复杂游戏中的应用取得突破。这些事件将人工智能推向广泛关注的中心舞台。
2022年,OpenAI发布ChatGPT,生成式AI席卷全球。
注意:上述对于中国事件的罗列,只为在时间上的参照
人工智能技术体系中的层次结构
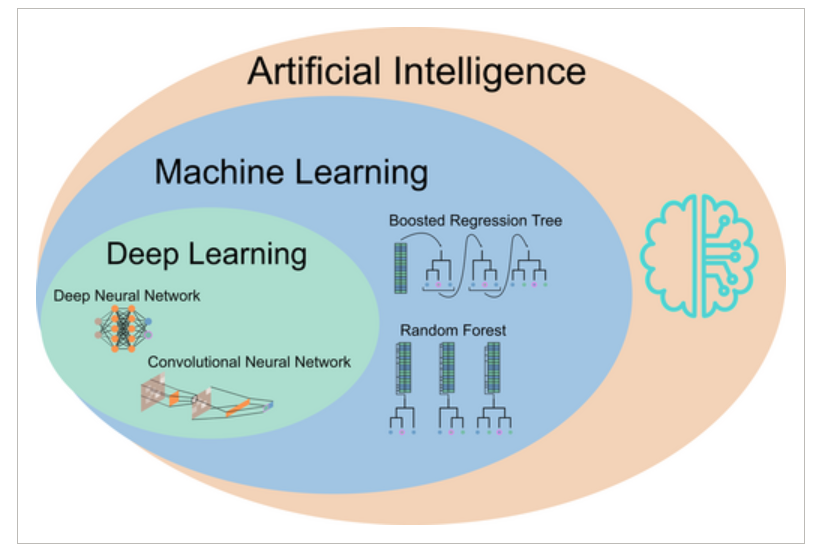
AI的目标是让机器具有人类一样的智慧,传统机器学习算法就是实现方式之一,其主要用于识别数据中的潜在模式。
前面列出了AI发展历程中的大事记,下面让我们看看ML的发展史。
1763, 1812:贝叶斯定理。
1805:最小二乘法。
1913:马尔科夫链。
1967:最近邻算法。
1970:反向传播算法。
深度学习作为机器学习的一个分支,其兴起主要源于AlexNet在视觉识别竞赛ImageNet中获得历史性的胜利。
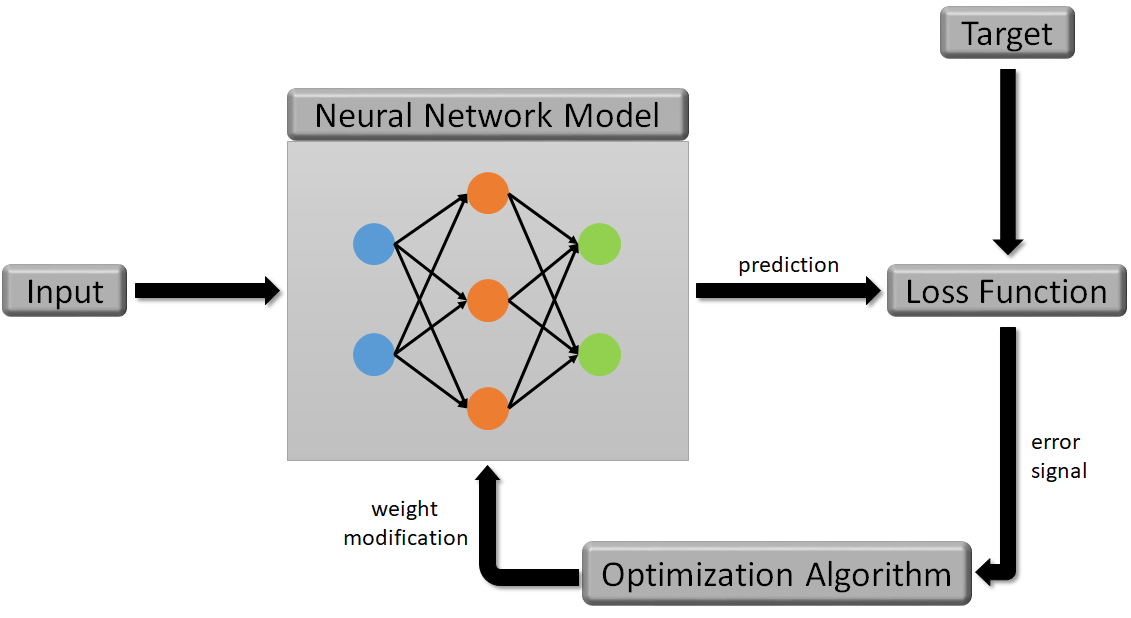
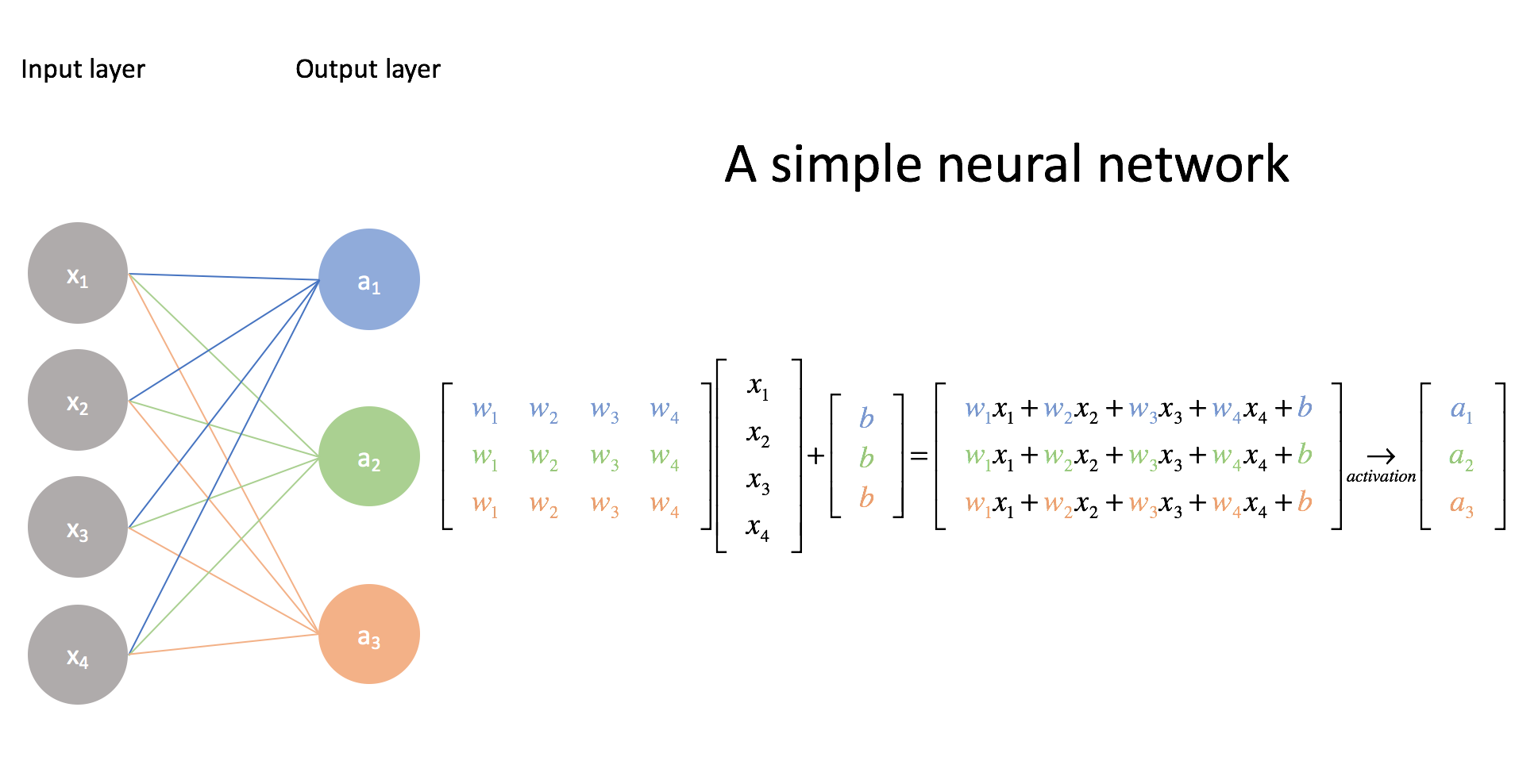
无论是传统机器学习还是深度学习,可以简化为三大要件:模型、优化算法和损失函数。
模型定义了输入和输出之间的映射函数。
损失函数用来量化模型效果的好坏。
优化算法则根据损失函数的量化结果调整函数的参数,使模型效果最优。
除了上面三大件外,数据也是重要组成部分。
传统机器学习和深度学习能够处理的数据形式稍有不同,传统机器学习善于处理数值特征,例如,使用线性回归预测房价中输入房间数,面积,是否临街等特征。
[3,80,1]
如果要用传统机器学习完成图像分类任务,则需要先手工对图片提取特征(SIFT,SURF,ORB,角点),然后再将特征输入到分类器中,例如SVM。
处理数据形式不同本质上是因为两者的模型架构不同,传统机器学习模型没有自动提取特征的能力。
深度学习则可以自动提取特征,CNN模型的架构使其非常适合处理图像这种需要考虑局部特征的数据形式,RNN则可以处理文本这种时序数据,深度学习中的ANN可以直接处理房价预测任务中数值特征。
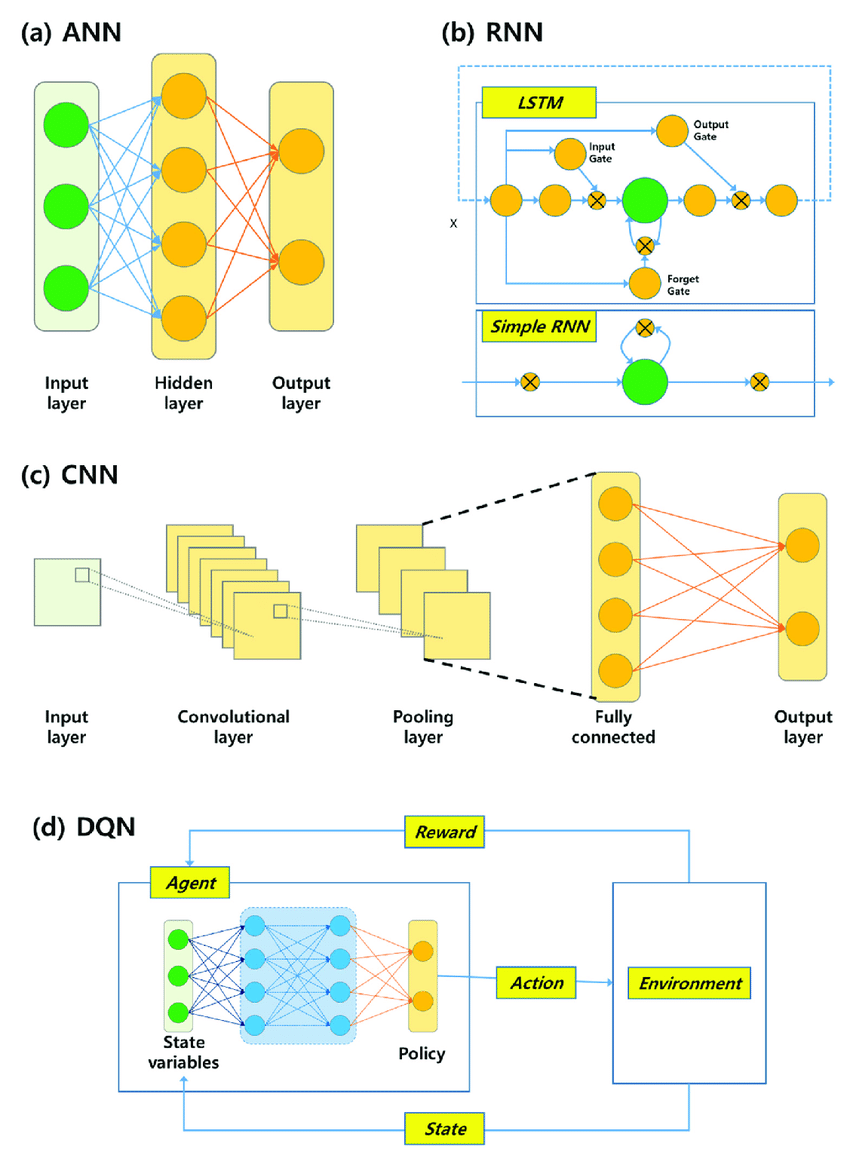
CNN中提取特征的部分通常称为骨干网络,最后根据特征来完成不同的任务。
例如,如果是图像分类任务,也就是图片入,类别出,则在骨干网上后面加上FC和Softmax.
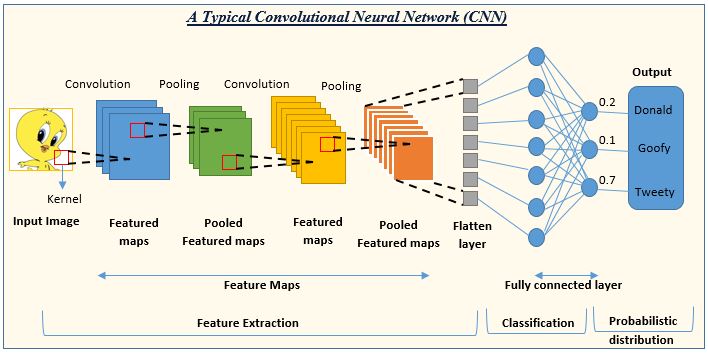
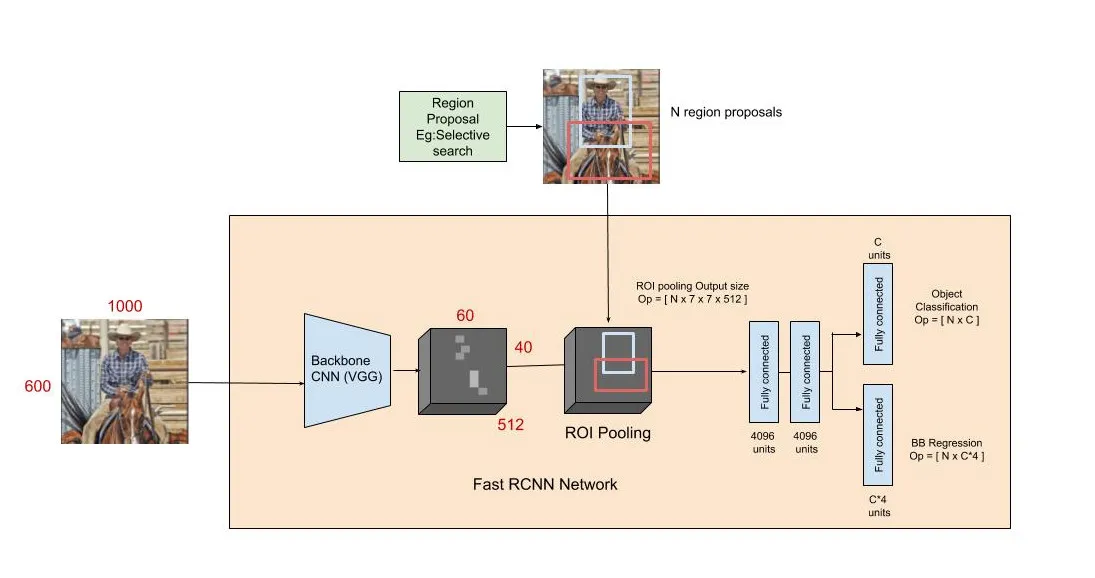
如果是目标检测,也就是图片入,检测框类别和位置出,则在骨干网络后加上分类和回归,目标检测模型有两个派别,一种是单阶段模型,以YOLO为典型代表,另一种是二阶段模型,以RCNN为代表。
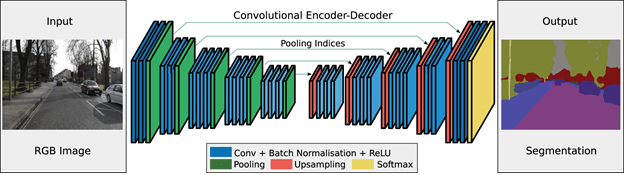
如果是图像分割,也就是图片入,图片出,则是一个FCN全卷积网络。
人类能说会看,机器也需要具备同样的能力,也正是前面讲的CNN和RNN奠定了深度学习在计算机视觉和自然语言处理这两个领域的成功应用基础。

AI的数学原理
上层建筑离不开坚固的地基,任何一门技术也要有理论基础,AI也是如此。
在机器学习中应用非常广泛的贝叶斯定理,最小二乘法,马尔科夫链,在AI出现很早以前就有了,它们源于数学和统计学领域,作为一般数理工具。在其他领域均有应用,并非专为AI而生。最小二乘法用于拟合模型参数,贝叶斯用于推断概率和更新信念。
这也正好契合了机器学习的数学基础和思想,AI的数学原理主要包括线性代数,概率与统计,微积分,数值优化。
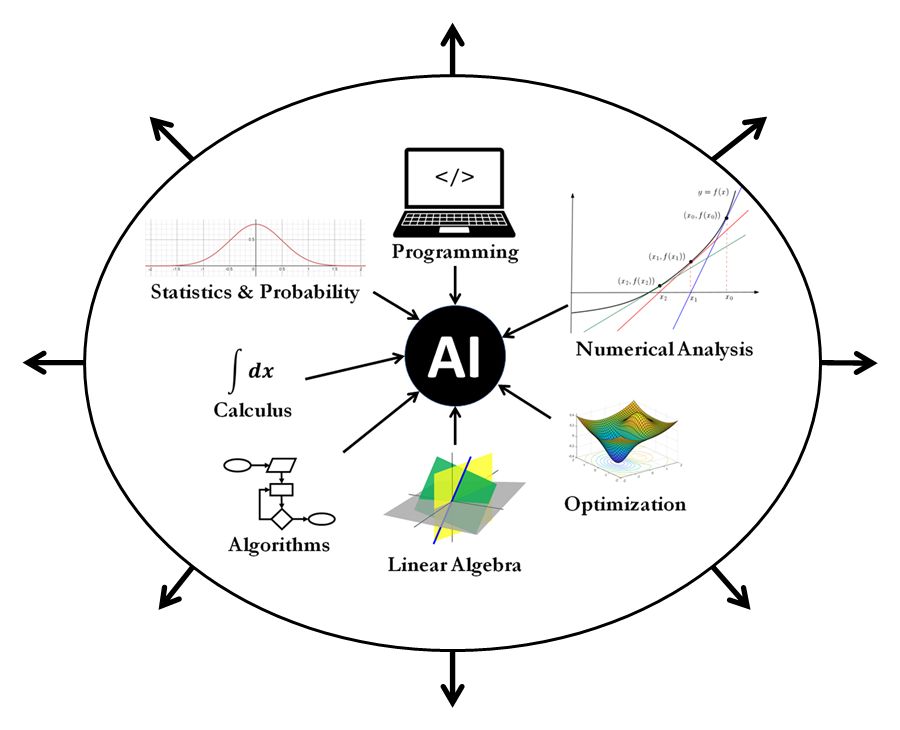
数值化通过将数值、图像、文本数据统一表示成线性代数中的向量和矩阵,使其可以利用矩阵运算等线性代数工具进行处理。
概率论和统计学为AI系统建模不确定知识和噪声数据提供了工具,最大化似然估计、最小化损失函数是求解参数的主要优化方法。
而微积分中导数和梯度概念,是构建和训练神经网络时调节权重的关键,反向传播机制依赖梯度下降实现参数优化。
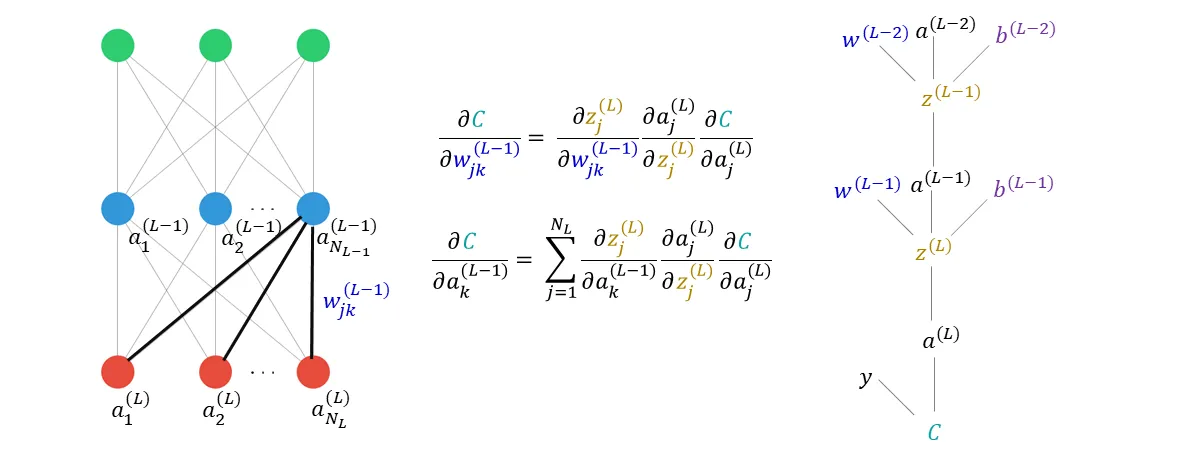
在AI的发展过程中,有两个东西曾被视为最有可能实现人工智能,但最终却以失败告终。
专家系统
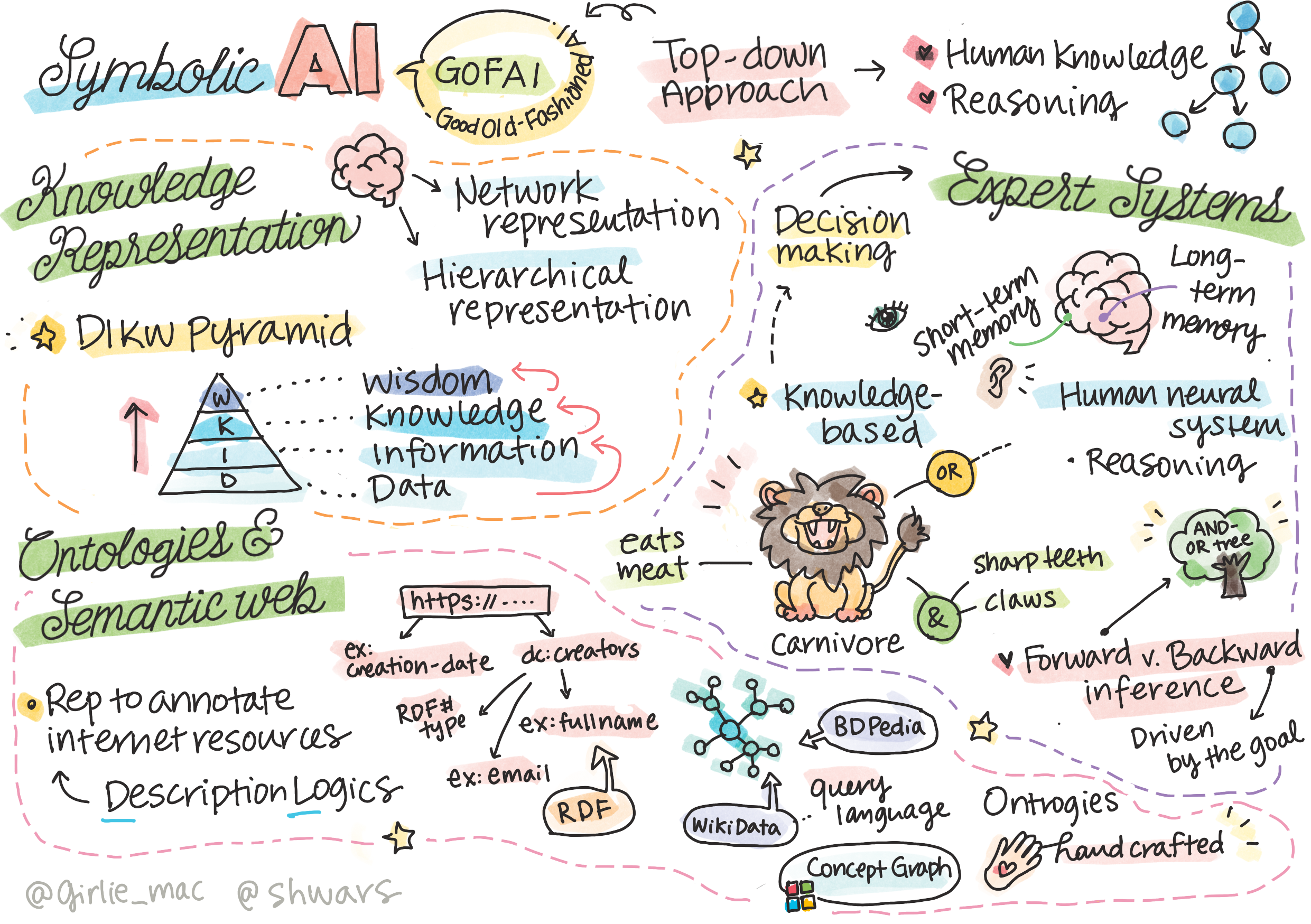
专家系统被称为符号主义AI的代表。
符号主义AI的核心是知识表示,将知识表示成计算机能理解的形式,什么是知识?我们要将数据,信息与知识的概念区分开,例如,我们可以通过学习书本成为专家,但书本上的只是数据。
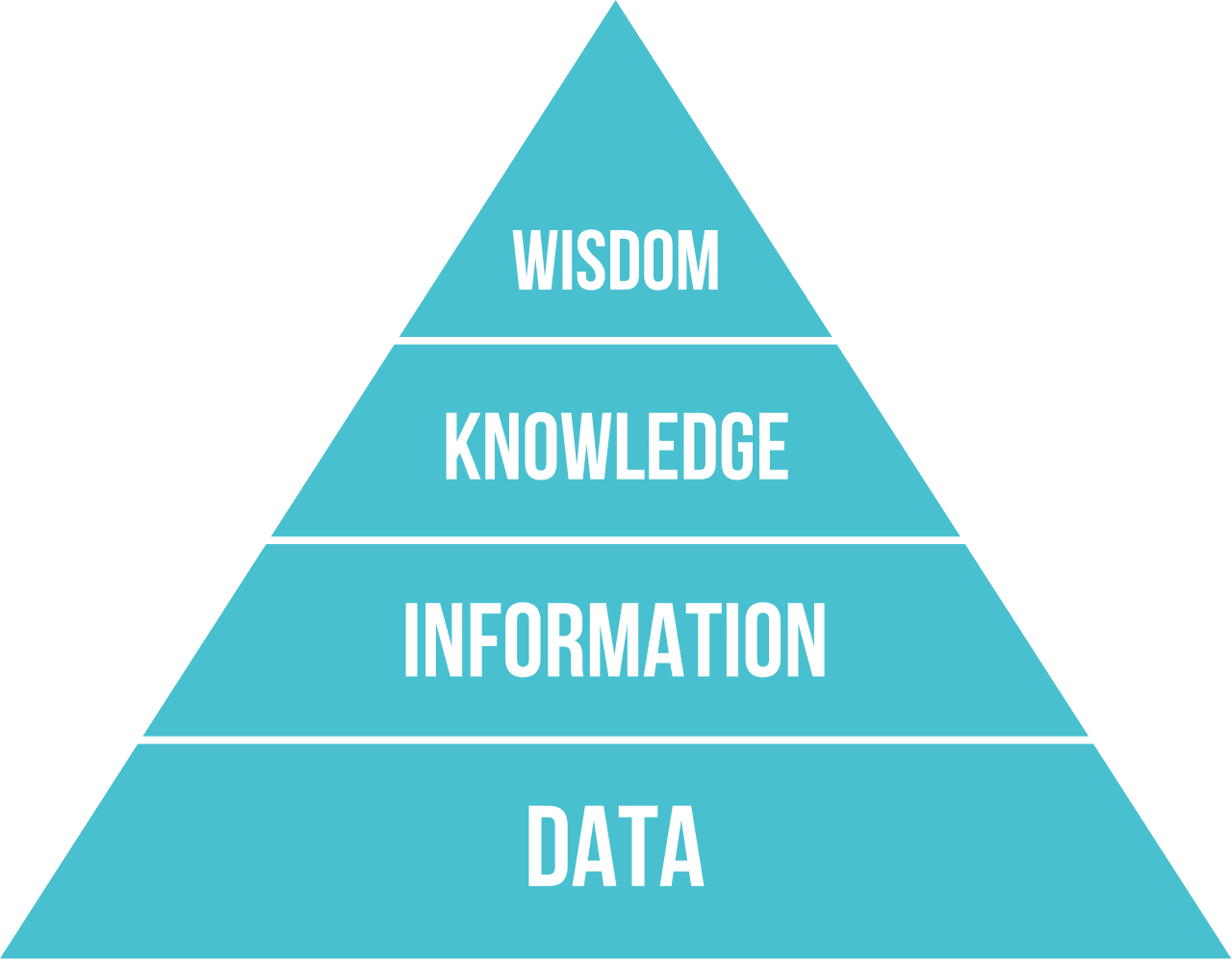
但从专家那里提取知识、将其表示在计算机中,并保持知识库的准确性,是一项非常复杂的任务,在许多情况下成本过高,难以实际应用。
其衰落直接导致了AI的第二次寒冬。
感知机

1957年,弗兰克·罗森布拉特发明感知机被视为神经网络的雏形,而神经网络则被视为连接主义的代表。
$y(x) =f\left( W^{T} x\right)$
f是阶跃激活函数。
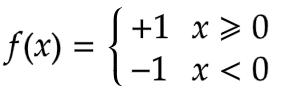
之后马文·明斯基等人指出弗兰克·罗森布拉特发明感知机无法解决异或问题。从今天的视角看,其本质是一个线性分类器,不能对非线性数据进行分类。
这一发现暴露了感知机和早期连接主义人工智能的局限性。但这并不意味着人工智能本身存在障碍,它也促进了新的神经网络算法的产生,为后来兴起的深度学习埋下了伏笔。
现在的前馈神经网络与罗森布拉的感知机相比,只是使用了非线性激活函数以及更深更宽的网络结构,如果罗森布拉特当初能继续尝试,他都有可能创造历史,因为根据万能逼近定理,即使单隐藏层的前馈神经网络也可以逼近任何连续函数。
通过AI的发展历程可见,任何一种新兴技术的发展都不是一蹴而就的。AI的发展并没有因为寒冬而戛然而止,实时证明人工智能是大势所趋。
被视为第四次工业革命核心的人工智能,必将是时代发展的必然产物。