 人工智能大讲堂
人工智能大讲堂
我呆看窗外,熙攘的街景映入眼帘,街边的叫卖回荡耳边,细数过往的车辆,脑子却反复模拟明天相亲的场景,心理一直就是否应约做斗争,对方是一位身材高挑的妙龄少女,突然手机屏亮,是媒人发来催促的信息,最终,我决定抛硬币来决定命运。
佛语有云,看山是山,看水是水,我看这段话是一段苦情小伙的内心告白,而在别人眼里,它却是承载丰富信息数据的生成过程。
这段文字包含的数据形式有表格(妙龄,熙攘),图像(街景),声音(叫卖),文本(信息),产生这些数据的方式包括测量(数车辆),传感器(眼睛看街景,耳朵听叫卖),实验(抛硬币),模拟(模拟相亲场景)。
现实中的数据也大抵如此。
好了,暂时回到AI的主题,人类靠眼睛感受世界,靠语言表达情感,靠倾听获取诉求,靠数字做出决策,人工智能的目的是要让计算机充当人类的眼睛,耳朵和嘴巴。但计算机是个异类,在它的世界里只有0和1这样的数字,所以要实现这个目的,第一步就是要数字化,也就是图像,语音,文本,表格数据的采集和存储。
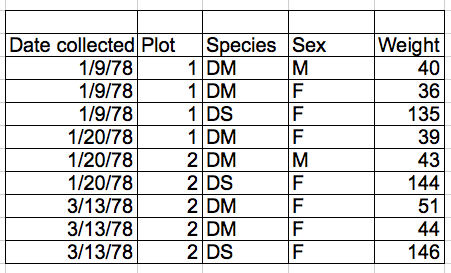
表格数据
最简单的就是表格数据了,我们经常用数字去凸显事物的特征,像人的身高,体重,年龄,学历;房子的面积,房间数,距离地铁的距离;这类数据之所以称为表格数据,是因为可以将其记录在像Excel这种表格里。
数字特征一般可以通过简单的计算和测量进行采集,但有的也需要一些复杂的统计方法。表格数据一般通过Excel,数据库等工具按照某种编码方式转换成二进制储到计算机硬盘。
在使用表格数据时,一般通过Pandas将其加载到内存中,可以通过matplotlib进行可视化,最后将其转换成Numpy格式或者机器学习框架内在数据格式,通常是二维数组或者列表,集合;数据的每一行表示一个人或者一间房屋,每一列则是特征。
通过每一行数据你只能了解一个人或者一间房屋的信息,但机器学习研究的是群体,是从一大堆数据中发现规律,为此,训练之前还要进行预处理,也可以称之为特征提取,比较重要的操作包括利用相关性分析去掉重复列或者与结果不相关列,使用PCA进行降维来保留最重要的特征。
最后使用传统机器学习或者前馈神经网络对这些数据进行分类,回归,或者聚类等任务。例如,预测泰坦尼克号上游客的生存状况就是一个二分类问题,加利福尼亚房价预测就是一个回归问题。
图像
现实生活中很多科技发明都源于自然的灵感,例如,飞机源于鸟,声纳源于海豚。
人类可以通过眼睛感知外面的世界,这种能力当然不能被忽视,相机的灵感就是源于人类的视觉系统。
目前还没有方法能将人眼看到的东西从大脑中提取出来显示到电脑中(听说马斯克正在搞的脑机接口有望实现此功能),但相机可以,快门一按,一幅数字图像就产生了(注意,这里主要指的是数码相机而不是胶卷相机)。
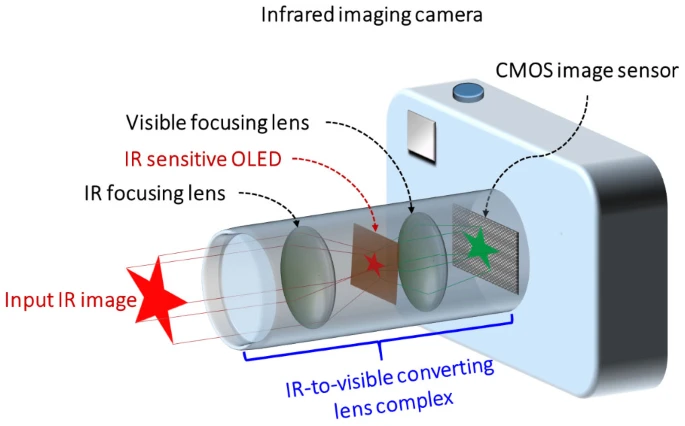
瞳孔 <-> 光圈,晶状体 <-> 镜头,视网膜 <-> 感光元件,大脑 <-> 存储器
最终我们就得到了下面这个图像矩阵。
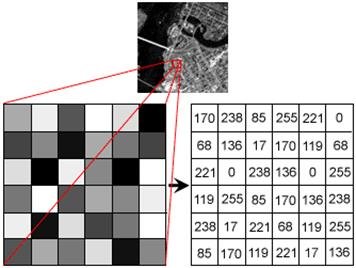
最近遥遥领先发布了搭载国产芯片的手机,瞬间燃起轩然大波,有不少买了新手机的发烧友都在朋友圈炫耀新手机拍的图像!
对于成像的质量,其实关乎很多技术细节,这里主要介绍三个关键概念:相机分辨率,图像分辨率,显示器分辨率等等,
先来看下ChatGPT对这三个概念的解释。
-
相机分辨率:这是指相机的感光元件上的感光单元的个数,也就是相机的像素数。相机分辨率越高,意味着感光单元越多,能够记录更多的细节和信息,但也会占用更多的存储空间。相机分辨率通常用百万像素(megapixel)来表示,比如2000万像素,4000万像素等。
-
图像分辨率:这是指数字图像中存储的信息量,也就是图像的像素数。图像分辨率越高,意味着图像包含的像素越多。
-
显示器分辨率:这是指显示器的屏幕的像素组成的数量,也就是显示器的像素点。显示器分辨率越高,意味着像素点越多,显示的画面就越清晰,视觉效果就越好。显示器分辨率也可以用PPI或者DPI来衡量,或者直接用像素数来表示,比如1024×768,1920×1080等。
相机分辨率,图像分辨率,显示器分辨率之间的联系是:
相机分辨率决定了能够捕获的细节的多少,也就是说,被拍摄物体每单位面积所包含的像素数,相机分辨率很大程度上决定了图像质量的好坏。
对于图像分辨率,是不是越大越好呢?我们都知道可以通过软件缩放来改变图像的大小,例如,将2*2的图像放大到一万倍,但简单的插值方法生成的像素没有增加细节,徒劳无功。
这时,有人会站出来反驳,图像插值太low了,现在都用深度学习技术对图像质量进行优化,所谓硬件不够AI来凑,例如,使用生成式AI生成高质量图像,图像超分辨率,图像修复,图像风格迁移等,但AI是否能真正弥补硬件的不足,我没试过,这里就留给大家思考吧。
接下来做一些科普,你知道一幅从太空传回来的图像能有多大吗?科学分析中使用的是高分辨率深空图像,可以达到几GB数据量级,深空相机则可以采集一亿像素以上的图像。
图像分辨率也决定了图像在显示器上的显示效果,也就是说,图像的像素数要和显示器的像素点相匹配,才能达到最佳的清晰度。如果图像分辨率高于显示器分辨率,那么图像就会被缩小,可能会失去一些细节;如果图像分辨率低于显示器分辨率,那么图像就会被放大,可能会显得模糊或者锯齿状。
至此,图像的采集工作就完成了,采集完成后一般将其保存成某一种格式,常见的图片格式包括JPEG,PNG,GIF,TIFF,SVG,代表不同的压缩方法。
图片分为灰度图和彩色图,灰度图是一种只有亮度信息,没有颜色信息的图像,每个像素的值表示其灰度级别,通常从0(黑色)到255(白色);彩色图是一种有颜色信息的图像,每个像素的值表示其在某种颜色模式下的颜色分量,例如RGB(红绿蓝)或CMYK(青品红黄黑)。


在使用图像时,首先需要将其从磁盘中加载到内存,很多工具都能读取图像,例如OpenCV,PIL等,在开始训练之前,还要将其转换为机器学习框架认识的数据格式,可以使用Numpy数组,或者是机器学习框架内置的数据结构。
这里要给大家提个醒,对于彩色图,有三个颜色分量,此时就需要考虑内存布局问题,不同的框架,对于RGB图像的存储方式是不一样的。
通道的顺序:有些框架是按照RGB的顺序存储的,比如Matlab,PIL,TensorFlow等;有些框架是按照BGR的顺序存储的,比如OpenCV,Caffe,PyTorch等。这会影响到图像的显示和转换,需要注意调整通道的顺序。
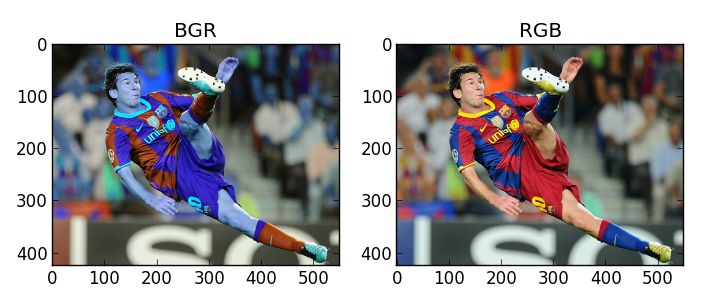
通道的排列:有些框架是按照通道优先[channels, height, width]的方式存储的,比如Caffe,PyTorch等;有些框架是按照通道后[height, width, channels]的方式存储的,比如Matlab,OpenCV,TensorFlow等。这会影响到图像的维度和处理,需要注意调整通道的位置。
[height, width, channels]表示通道最后的布局。即图像中的像素点按高度方向,然后宽度方向,最后颜色通道方向顺序存储。这是一种行优先的布局。
[channels, height, width]表示通道最先的布局。即先存储所有的红色通道像素,然后绿色通道,最后蓝色通道。这是一种通道优先的布局。

通道的范围:有些框架是按照0~255的整数值存储的,比如OpenCV,PIL等;有些框架是按照0~1的浮点数存储的,比如Matlab,TensorFlow等。这会影响到图像的数值和计算,需要注意调整通道的范围。
为了增加模型泛化性能,往往还需要对图像进行增广操作,例如,缩放,旋转,这就会涉及到像素插值,但不同的框架即使是同一种插值方法,实现也不尽相同。例如,pillow和opencv的resize就不一样。所以,当你遇到不同推理方式结果存在些许差别时,不妨往这方面想想。
将图像加载到内存后就可以进行后续任务了,例如,训练一个图像分类,目标检测,图像分割模型。
在表格数据那一节我们提到了对数据进行预处理提取特征,那对于图像需要提取特征吗?有的人可能会说,我在训练或者推理时都是输入的原始图像啊!没提取什么鸟特征啊!
先不回答这个问题,先做个小游戏,如果让你看一幅猫的图像,问你这是啥?你说这是猫,看狗,你说这是狗,此时我问你为什么?你说:猫就是猫,狗就是狗,哪有为什么,其实不然,在你看图识物过程中你大脑在背后执行了很复杂的操作,这其中就包括提取特征的过程,也正是这些特征才让你看猫是猫,看狗是狗。
计算机看图识物也需要图像特征。 那特征是怎么来的呢?
在深度学习没有出现之前,需要依赖人的经验提取图像特征,然后将提取的特征输入到机器学习模型中进行分类或者目标检测等后续任务。
最简单的图像特征,数字图像处理课上的边缘检测器,能够检测特征线。
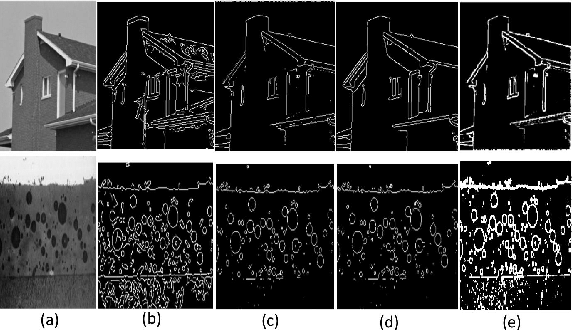
再复杂一点的,如SIFT,Surf,HOG,ORG,角点等,能够检测特征点。

有了卷积神经网络后,ReseNet,GoogleNet,Inception等,这些被称为骨干网络的家伙通过卷积层和池化层能够自动提取特征,输出结果我们称之为特征图,它反映了输入图像在某些特征上的响应程度,例如边缘、纹理、形状等。
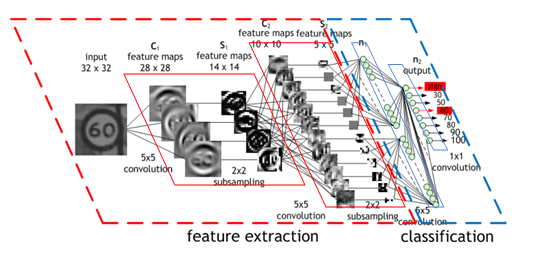
目前也有一些能够检测特征点的深度学习模型,例如,SuperPoint。
其实,不光是图像分类,目标检测,图像分割,还有很多任务都需要依赖图像特征,例如,相机校准,图像拼接,SLAM等等,所以对于图像处理,是高度依赖图像特征的。
声音
声音是模拟信号,是一种由空气或其他介质中的压力变化产生的机械波,通过外耳道进入人类的耳朵,到达鼓膜,使鼓膜振动,基底膜上的毛细胞随着基底膜的振动而弯曲,产生电信号,这些电信号就是听觉的神经冲动。
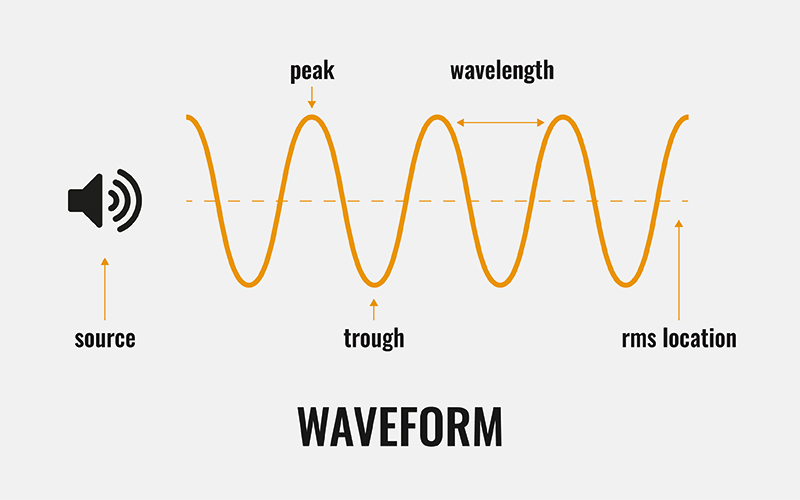
我们知道计算机中只能存储数字,那计算机是如何存储音频的呢?或者换句话说计算机如何存储模拟信号呢?
计算机存储声音的方法是使用采样和量化的方式将声音信号转化为数字形式。
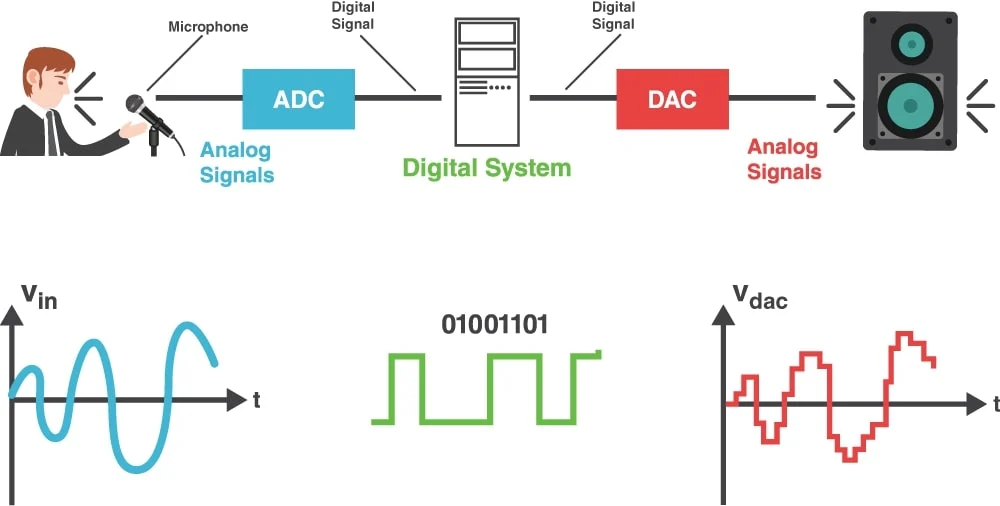
具体来说主要包括以下几个过程:
-
采样:先使用ADC(模数转换)对声音信号以一定的频率(采样频率)进行采样,获取波形振幅。
-
量化:将采样得到的连续振幅值量化为离散的数字量,一般使用8bit、16bit等量化比特数。
-
编码:将量化后的样本数字编码压缩为特定格式的音频数据,常见的编码格式有WAV、MP3、WMA等。
-
存储:最终以二进制数字数据的形式存储在计算机存储介质中。
播放时则进行反向解码转换为模拟信号输出。
采样和量化保证了声音模拟信号向数字信号的高精度转换。编码格式的选择则关乎音质和文件大小的平衡。这就是计算机存储和处理音频信号的基本方法。
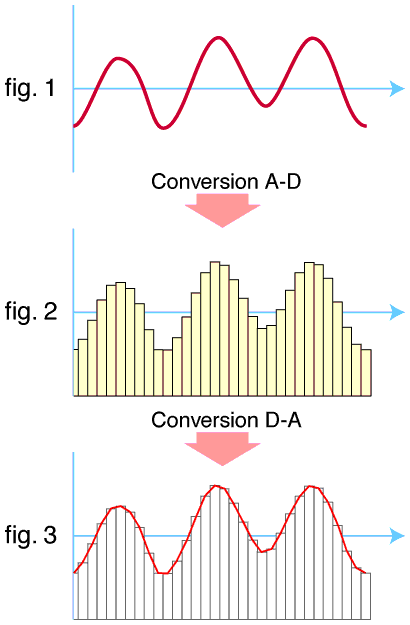
同样在原始声音数据的基础上,也可以进一步提取特征。
最简单的就是从原始声音数据入手,例如,反映语音波形本身在时间轴上的振幅变化特徵,比如短时能量、过零率、声音幅度的包络曲线等,这类特征我们称之为时域特征。
像声音这种时域数据还存在频率维度,在频率维度存储了反映语音特性的特征重要参数,在频率维度提取到的特征称之为频域特征。将时域数据转换成频域数据需要借助一个工具:傅里叶变换,通过对语音信号做傅里叶变换,转换到频域,得到的语音频谱信息,反映不同频带能量特征。常用的有滤波组功率、Mel频率倒谱系数(MFCC)、线性预测倒谱(LPCC)等。
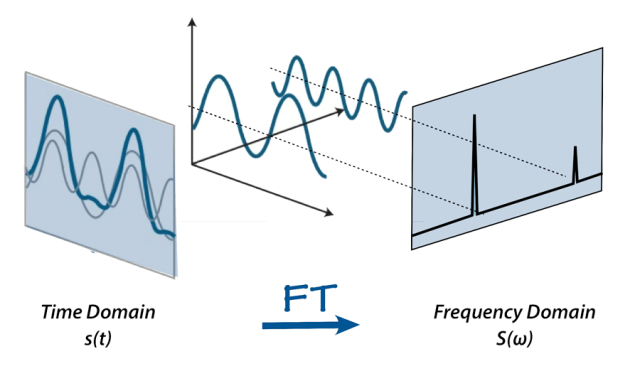
其实,图像也可以通过延拓或重复的方式构造出周期图像,这样就可以对图像进行傅里叶变换,转换为离散的频谱,这样就可以对不同频率分量进行单独处理,利用高低通滤波实现图像的平滑和锐化。

如上图,左下角为原图像经傅里叶变换后的频谱图,中心的是低频分量,边缘的是高频分量,右下角图像过滤掉高频分量后,图像会变得平滑模糊,这是因为高频分量包含了图像的边缘和细节信息,而低频分量包含了图像的主要部分和平坦区域信息。
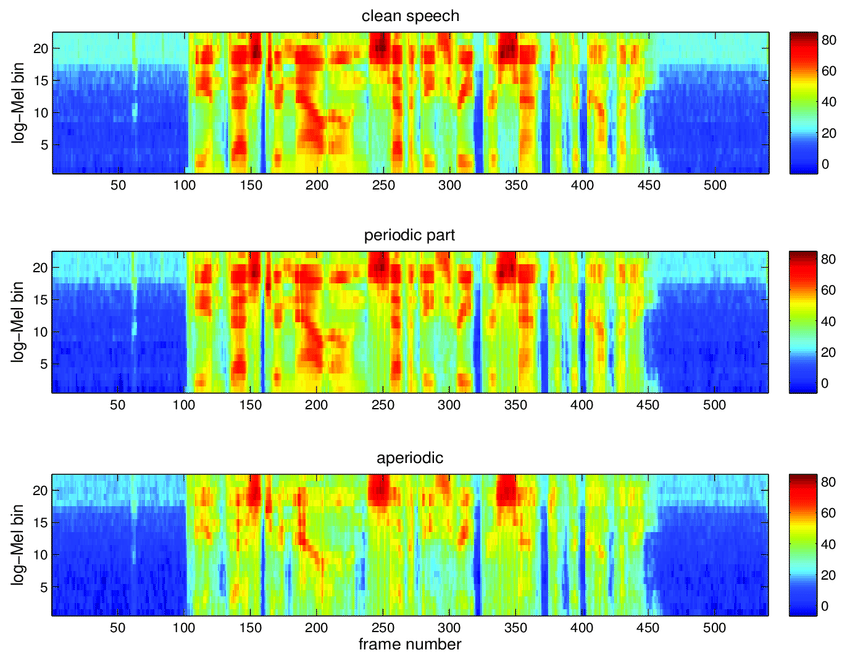
Openai在2023年11月份升级了ChatGPT,升级后,不仅可以输入文字,还可以通过语音与其对话, 这背后其实是OpenAI另一个语音识别模型:Whisper。
Whisper模型的输入就是Log-Mel Spectrogram声音特征。
要获得 Log-Mel Spectrogram,需要经过以下数字化处理:
-
对模拟语音信号进行采样,获取数字化离散信号(discrete signal)。
-
对数字信号做快速傅立叶变换(FFT),转换为频谱(spectrum)。
-
对频谱应用Mel标度滤波器组,获取Mel频谱(Mel spectrum)。
-
计算Mel频谱的对数,得到Log-Mel频谱(Log-Mel spectrum)。
-
将Log-Mel频谱的每一帧在时间轴上排列,形成Log-Mel Spectrogram。
如果你还不理解Log-Mel Spectrogram没关系,说白了,Log-Mel Spectrogram就是类似于图像的二维数组。横轴是时间维度,纵轴是每一时刻声音特征。
这里说到了语音识别,就再多说几句,你在B站还有油管上看到的字幕功能,使用的就是一种语音识别技术,除了识别,还能翻译,而且,在Whisper中,从源语言到英语的翻译是端到端的,并不是先识别源语言,再将识别的源语言翻译成目标语言。
文本
文字应该是生活中使用最多最频繁的,人类文明在很早之前就有使用文字的记载,我国的仓颉造字,不同国家也发展了自己的语言系统,汉语更是博大精深,一词多义,一语双关,这虽然让文字量可以控制在有限范围内,但这给计算机却带来了很大麻烦。
但我们先不说一词多义的事,这个会在Transformer中的注意力机制涉及到,我们要先弄明白文字是如何在计算机中存储的?其实在表格数据中已经讲过文本的存储了。就是使用字符编码来将字符转换为数字代码进行存储。常见的字符编码方法有:
-
ASCII码:使用英文字母、数字、符号对应固定的数字代码来表示,是最早的字符编码。
-
Unicode码:国际通用的字符编码,将全世界大部分的文字和符号都映射为数值代码。
-
GB2312码:简体中文常用的字符编码方法。
-
各国文字的国家标准码:如支持日文的Shift-JIS码等。
在保存文本时,操作系统会根据指定的字符编码,将文本的文字转换为对应的数字代码序列,以比特流的形式保存在文件或者数据库中。
读取文本时再根据编码映射规则,将存储的数字代码解析还原为相应的文字。
这就是计算机存储文字的基本方法。不同encoding的区别在于支持的文字数量和映射表的大小。利用数字编码来存储文字是计算机处理文本的基础。
根据以上的编码规则,”I love china”这个字符串分别用不同的编码方式表示如下:
ASCII编码:01001001 00100000 01101100 01101111 01110110 01100101 00100000 01100011 01101000 01101001 01101110 01100001
UTF-8编码:01001001 00100000 01101100 01101111 01110110 01100101 00100000 01100011 01101000 01101001 01101110 01100001
UTF-16编码:00000000 01001001 00000000 00100000 00000000 01101100 00000000 01101111 00000000 01110110 00000000 01100101 00000000 00100000 00000000 01100011 00000000 01101000 00000000 01101001 00000000 01101110 00000000 01100001
Unicode编码:00000000 01001001 00000000 00100000 00000000 01101100 00000000 01101111 00000000 01110110 00000000 01100101 00000000 00100000 00000000 01100011 00000000 01101000 00000000 01101001 00000000 01101110 00000000 01100001
有人会问了,能将“我爱中国”编码成ASCII编码吗?
答案是不能,ASCII码是一种用一个字节(8位)表示一个英文字符或符号的编码方式。它只能表示128个不同的符号,汉字的数量非常庞大,远远超过了ASCII码能表示的范围。因此,不能将汉字编码成ASCII码,为了让计算机能够处理汉字,人们开发了各种汉字编码方式,例如GB2312,GBK,GB18030,BIG5,Unicode等。
“我爱中国”的GB2312编码是0xCE 0xD2 0xB0 0xAE 0xD6 0xD0 0xB9 0xFA。
“我爱中国”的GBK编码是0xCE 0xD2 0xB0 0xAE 0xD6 0xD0 0xB9 0xFA。
“我爱中国”的GB18030编码是0xCE 0xD2 0xB0 0xAE 0xD6 0xD0 0xB9 0xFA。
“我爱中国”的BIG5编码是0xA7 0xDA 0xB0 0xDA 0xB3 0x6F 0xA4 0x40。
“我爱中国”的Unicode编码是0x6211 0x7231 0x4E2D 0x56FD。
好了,到此我们已经能够将字符编码成数字了,如果要训练一个大模型,直接把文本分割成字符,然后进行编码,最后将这些数字直接扔给模型不就可以了?
字符编码并不合适,字符编码的向量维度很高。
既然说字符编码维度高,那就换个方法,但还是以字符为单位。
通常英文字母表包括26个英文字母(不区分大小写)和空格,共27个字符。因此,我们需要用一个长度为27的二进制向量来表示每个字符。
其次,我们需要将每个字符映射到一个整数值,一种简单的方法是按照字母表的顺序,从0开始编号,即A对应0,B对应1,依次类推,空格对应26。因此,“I Love AI” 中的每个字符对应的整数值如下:
I: 8 L: 11 o: 14 v: 21 e: 4 A: 0 I: 8 空格: 26
最后,我们需要将每个整数值表示为一个二进制向量,其中只有对应的索引位置为1,其余位置为0。例如,0对应的向量为[1, 0, 0, …, 0],26对应的向量为[0, 0, 0, …, 1]。因此,“I Love AI” 中的每个字符对应的向量如下:
I: [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0,0, 0]
L: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0,0, 0]
o: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,0, 0, 0, 0, 0, 0, 0, 0,0, 0]
v: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 1, 0, 0, 0,0, 0]
e: [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0,0, 0]
A:[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0,0, 0]
I:[0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0,0, 0]
空格:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0,0, 1]
如果我们将这些向量拼接起来,就得到了”I Love AI” 的One-hot编码,它是一个长度为27×9=243的二进制向量。
这种方法虽然每个字符的向量长度减少到了27,但以字符为单位,如果文本很大,则整个数据量仍然很大。
所以,我们开始考虑以词为单位,因为词的数量也是有限的,可以构造一个词典,例如,牛津词典。然后对一个句子进行分词,最简单的,按照空格分词,每一个词都是一个向量,词典有多大,向量就有多大,如果这个词出现在词典的第二个位置,那么,这个向量的第二个位置就是1,其他均为0,这就是典型的one-hot编码。假设以词为单位,根据训练文本统计信息构造词典,假设词典中一共有10个词,I,Love,AI分别是词典中的第1,2,4个词。
“I Love AI” 的One-hot编码如下:
I: 1000000000
Love: 0100000000
AI: 0001000000
除了词,还有子词,因为和词的处理方式差不多,这里就不做过多介绍了。
不知道你发现没,无论是哪种方法,由one-hot编码构成的矩阵都是一个稀疏矩阵,如果词典很大,则无用信息占据了很大一块内存,内存利用率很低。
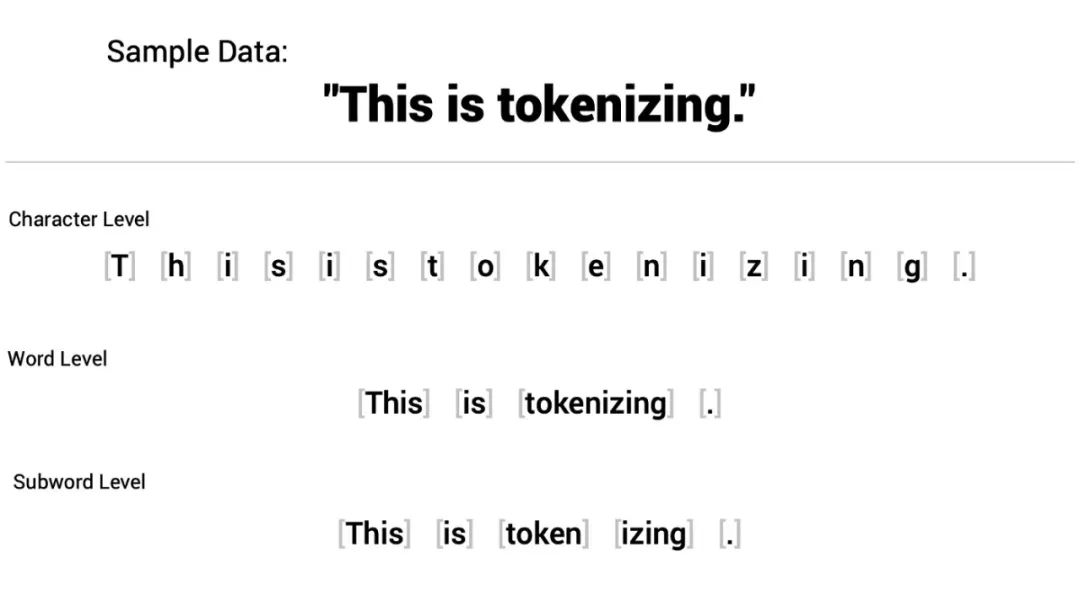
前面我们将文本划分成了字符,词,字词,这样一个个最小的语义单元我们称之为token,这个过程有一个好听的名字:Tokenlize。
word粒度
"I love AI"->token: [“I”, “love”, “AI”]
char粒度:
"I love AI"->token: [“I”, " “, “l”, “o”, “v”, “e”, " “, “A”, “I”]
subword粒度(BPE算法):
"I love AI"->token:[“I”, " lo”, “ve”, " AI”]
将token转换成向量的过程则被称为向量化,前面的one-hot编码就是一种向量化方法。
前面的表格数据,图像,语音,都有特征,那文字是否也有特征呢?当然有。
前面的one-hot向量化方法,是硬编码,无法体现语义信息。也就是语意相近的两个词,向量化后,在向量空间中离得很远,两个不相干的词却可能离得很近。
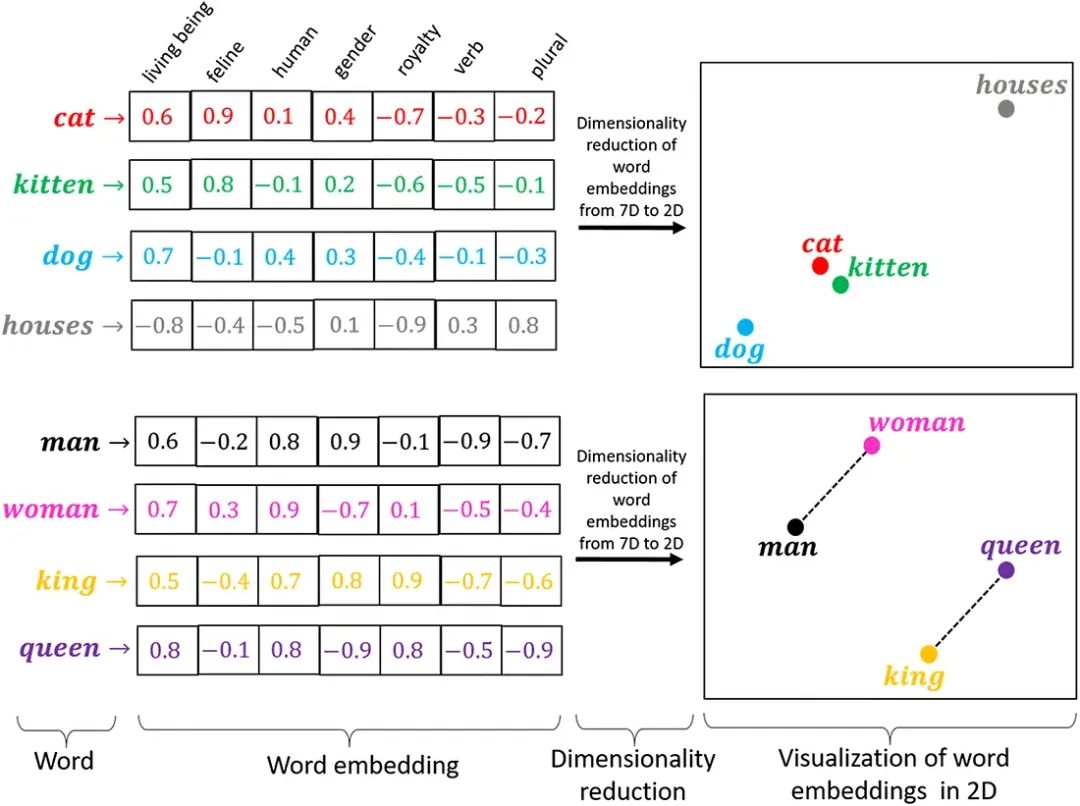
其实这里的语意信息就看作是文本的特征。
那如何提取语意信息呢?
词嵌入就是一种方法,词嵌入是一种软编码,因为它是通过训练学习得到的。

Wword2vec就是一种词嵌入方法。其主要思想是通过神经网络模型对大规模语料进行训练,训练完成后得到词向量矩阵。
例如,如果一个词表有4096个单词,每个单词用100维向量表示,如果使用one-hot编码词向量维度为词表大小,也就是4096,可见,词嵌入不仅解决了语音信息问题,还解决了维度问题,word2vec训练完成后就得到一个4096*100大小的矩阵,或者将矩阵构造成查找表,通过Tokenizer后的one-hot编码与词向量矩阵相乘或者根据位置索引查表就能得到词嵌入向量了。
到此,AI中所涉及到的四种数据形式的数字化就全部讲完了,不同的数据形式也发展出了不同的领域,例如,计算机视觉CV和自然语言处理NLP。
不同的数据形式也衍生出了AI的不同分支,例如,处理数字特征的前馈神经网络,处理图像的卷积神经网络,处理文本声音的循环神经网络。
一直以来,NLP都走在CV的前面。不论是深度神经网络超越手工方法,还是预训练大模型开始出现大一统的趋势,这些事情都先发生在NLP领域,并在不久之后被搬运到了CV领域。
例如,CV中的视觉Transformer就是借鉴NLP中的Transformer;CV中的无监督预训练方法最早也是在NLP中开始应用的。
NLP之所以能走在前面,要从下面几点讲起。
自然语言的基础单元是单词,而图像的基础单元是像素;前者具有天然的语义信息,而后者未必能够表达语义。自然语言是人类创造出来,用于存储知识和交流信息的载体,所以必然具有高效和信息密度高的特性;而图像则是人类通过各种传感器捕捉的光学信号,它能够客观地反映真实情况,但相应地就不具有强语义,且信息密度可能很低。
NLP在大语言模型火遍全球后,又漏了一把脸,大模型成功的背后,究其根本原因,除了Transformer模型架构外,还有一点不容小觑,我们都知道互联网上的文本数据多如牛毛,用互联网上的文本数据训练的模型,能很好的应用到你的私有数据上,也就是两者是同分布,人类语言是互通的,要表达的语义是相似的。但互联网上的图像训练的模型不能很好应用到你的私有图像上,两者差距很大。尤其是不同领域的图像,用ImageNet预训练模型微调后很难泛化到医疗图像。